偶遇 HTML 中的奇妙字符
本文最后更新于:2020年12月30日 凌晨
虽然名字听起来就像是一本正经的胡说八道,但吾辈确实遇到了一个奇怪的问题,于此分享给大家。
事情的起始如下
下班回家 => 想要看动画 => 去动漫花园下载 BT 种子 => 动漫花园一片空白 => Why?
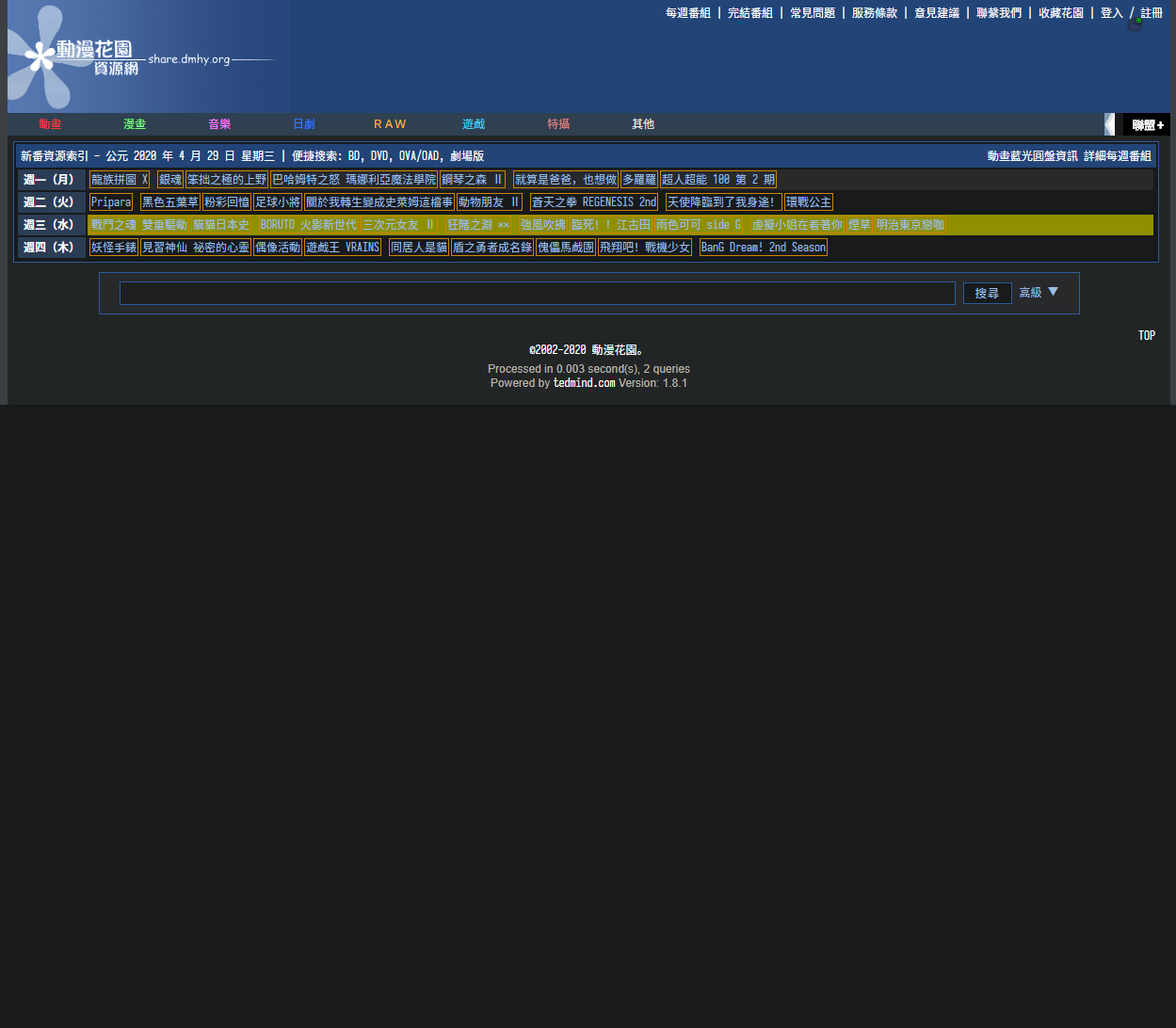
于是吾辈偷偷的的打开了控制台看了一下,发现是页面中的内容元素不见了。经过深思熟虑(好吧其实也就是稍微想了一下)首先把 uBlock 禁用,毕竟这个最容易被网站检测出来并且对抗嘛!果不其然,页面恢复了正常,但。。。同时广告也出现在了页面上。
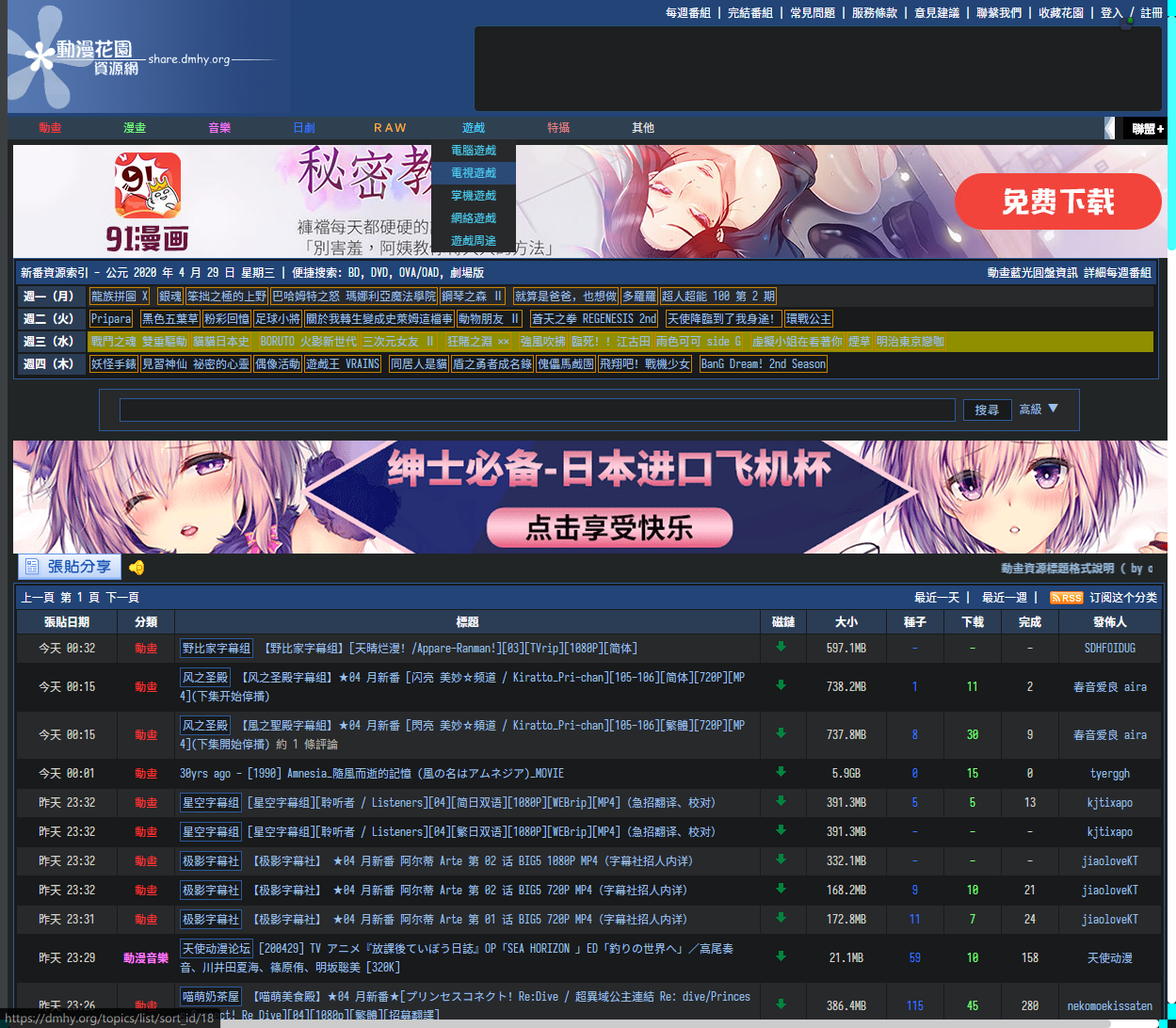
这可不行,重新启用了 uBlock 看了一下分析,很显然,内容不存在大概率是被 uBlock 的元素过滤功能隐藏掉了,查看被隐藏的内容元素,发现 id 为 1280_adv,但同时又包含了广告与主体内容,所以只要关掉 uBlock 的元素过滤就可以避免正常内容被误杀了。
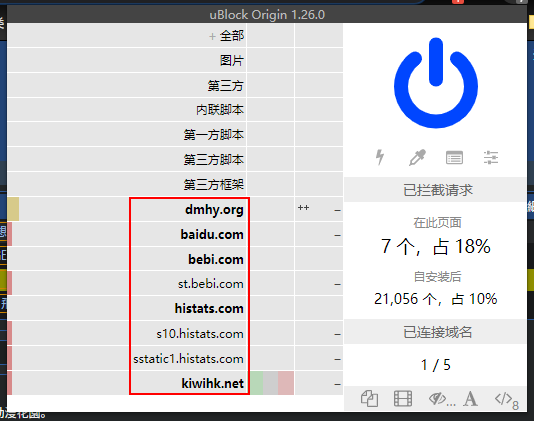
之所以不在该网站整个禁用掉 uBlock 的原因在于 uBlock 并不只有元素过滤,它还阻止了一些广告资源的加载,仅在动漫花园就包括但不限于 baidu.com, bebi.com, histats.com。显而易见,禁用它们还能提高加载速度。
既然无法使用 uBlock 的元素屏蔽了,那么吾辈便需要使用一个新的方式去阻止广告了,幸运的是吾辈安装了 Stylus 和 Tampermonkey 插件。
Stylus 能够使用被称为
user.css的技术,能够在本地修改任意网站的样式 – 即自定义 UI 显示。
而 Tampermonkey 则更强大,支持user.js– 可以在本地打开任意网站时载入自定义的 JavaScript 脚本,不再局限于修改 UI,几乎与插件无异(事实上它也确实被认为是更轻量的插件)。
原以为就几句 css 的事情,找到了广告的 id,于是吾辈写下了下面这些 css
1 | |
但结果却是。。。只生效了一半!
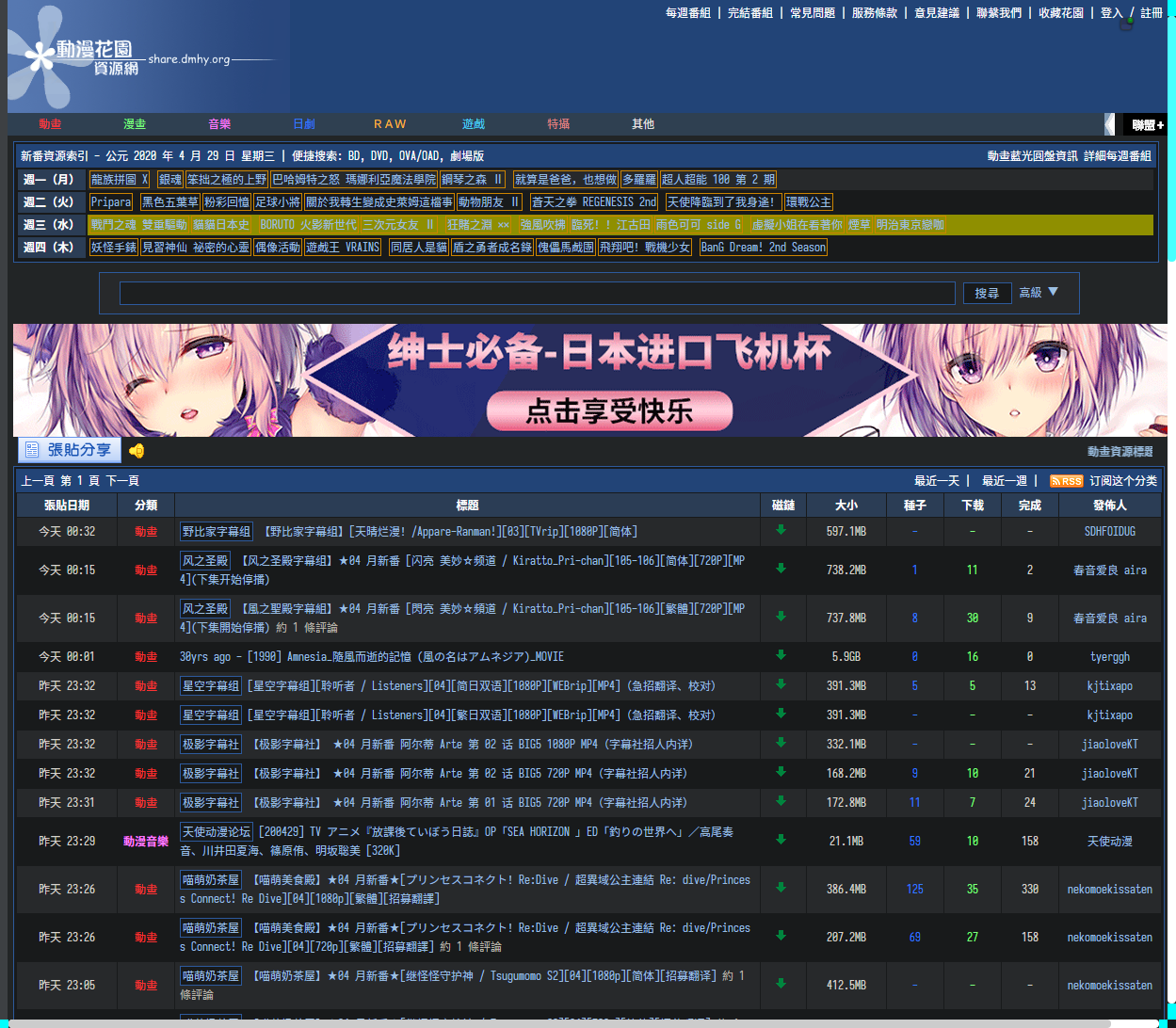
可以看到,上面两个广告确实被隐藏了,但下面一个却并没有,而且吾辈在控制台直接使用 document.querySelector('#1280_adv') 也获取 dom 会抛出错误 SyntaxError: Document.querySelector: '#1280_adv' is not a valid selector。吾辈是直接复制的 id,理论上来说不会有错才是。
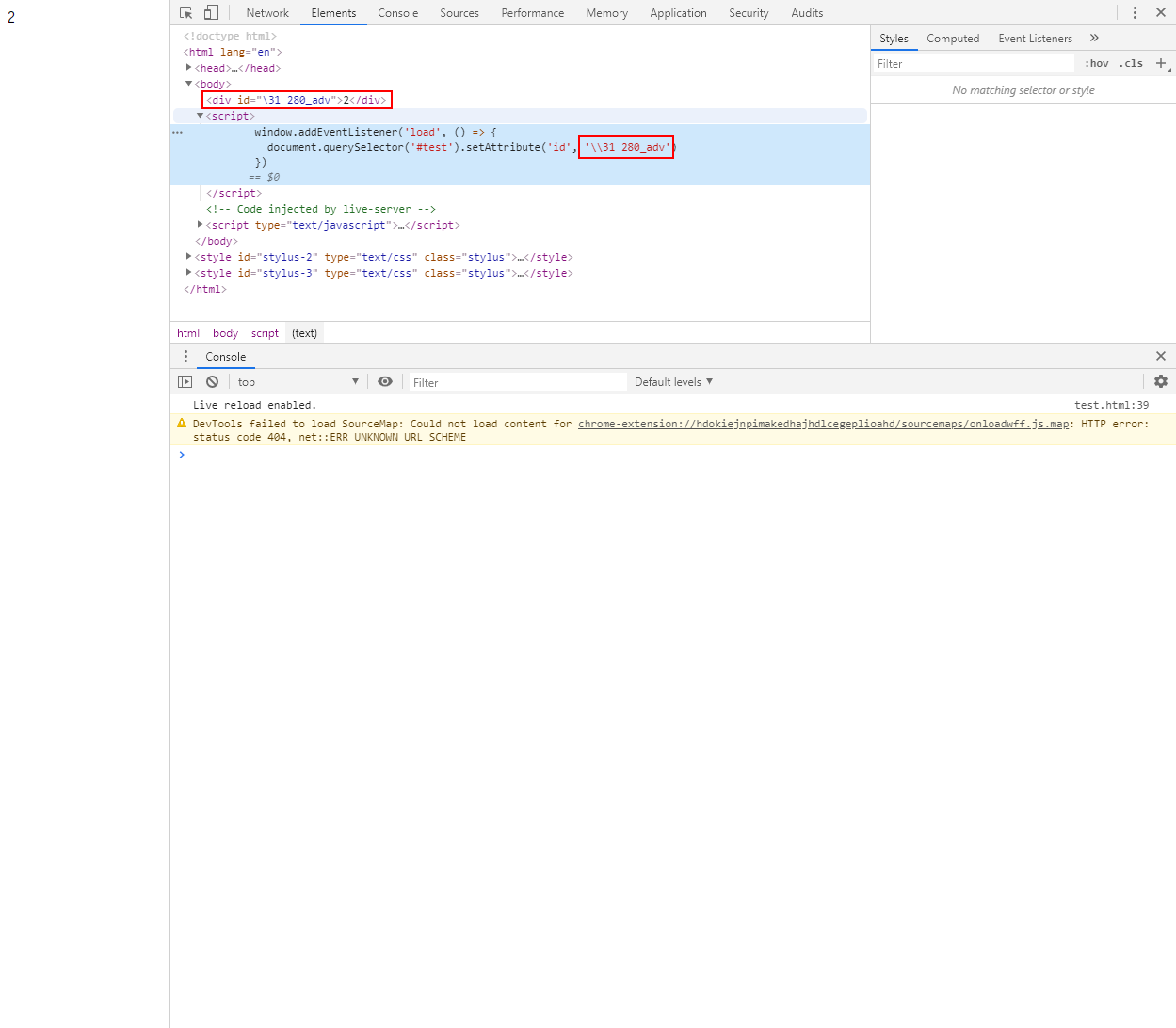
仔细想想,吾辈或许是漏掉了什么。。。于是,吾辈使用 Copy => Copy Selector 功能,有趣的东西出现了,复制出来的内容竟然是 '\31 280_adv',wtf?
嗯,或许吾辈需要冷静一下,尝试使用 document.querySelector("#\\31 280_adv") 获取一下
注意:这里 JS 里面去查询 DOM Selector 的字符串又进行了转义。
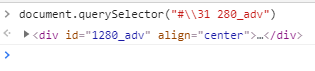
OK,确实能够正常拿到。由于这些奇怪的字符在 css 中存在语法错误,那么接下来便用 user.js 去屏蔽掉它们吧!
基本实现如下
1 | |
甚至吾辈都发到了 GitHub 与 GreasyFork 上了。
然后,有个(万能的)网友就提出,可以转换思路,既然 #\\31 280_adv 在 css 中存在语法错误,那么使用属性选择器过滤 id 将值包裹在 '' 之中不就好了么?此话真是九言劝醒迷途仕,一语惊醒梦中人,吾辈瞬间 GET 到了这个点。
于是吾辈编写出了下面这段 user.css 样式
1 | |
使用后效果如下
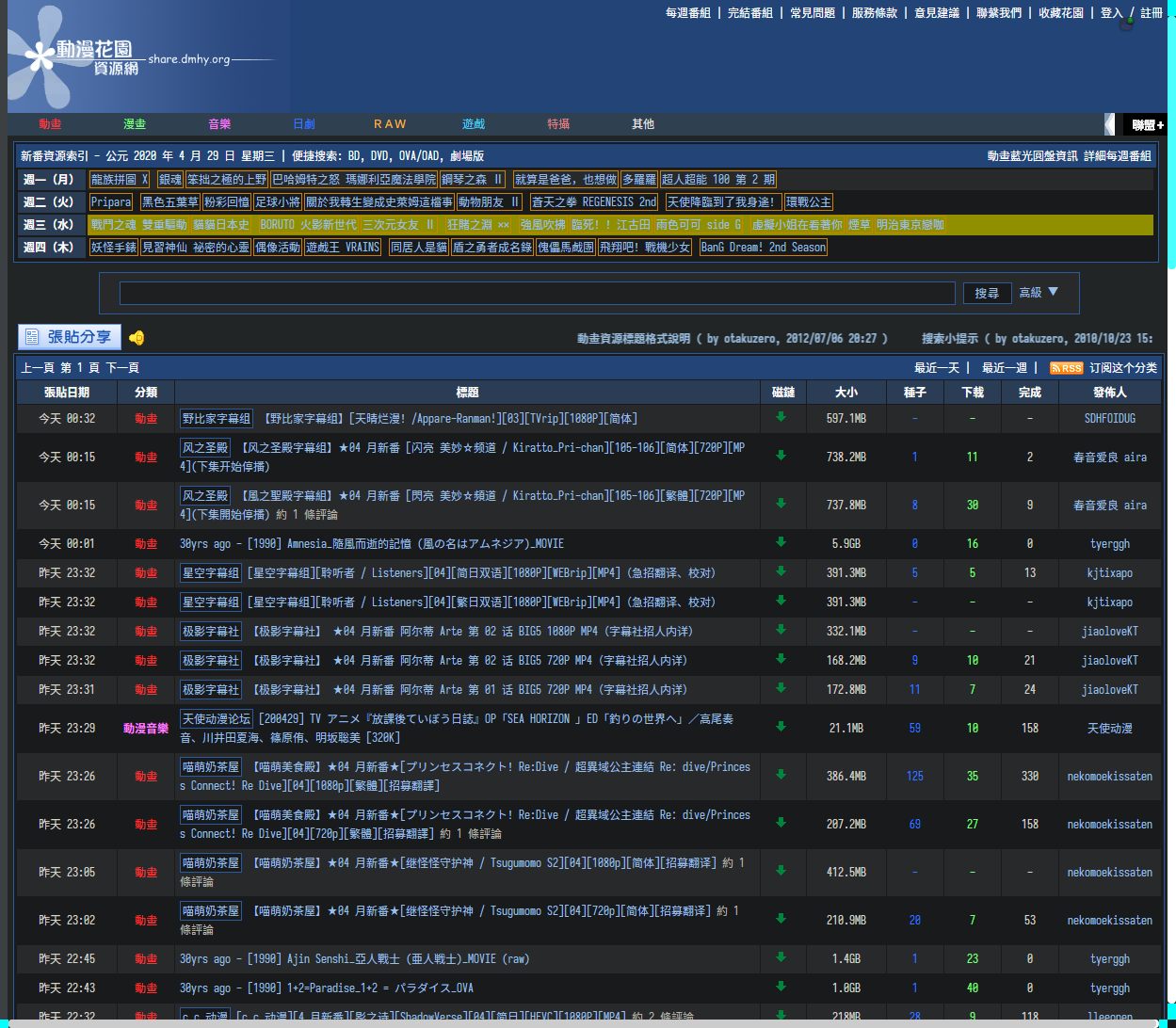
现在,初始目的达成了,吾辈开始有点好奇它是怎么实现这个功能,于是下载了它的源码,id 那里并未发现什么奇怪的东西,但吾辈却也无法复现一个 demo!
1 | |
demo 效果
如果有人知道原因的话,请务必不吝赐教!
参考:ASCII Wiki
后续,万能的网友 NiaMori 又来说明啦,实际上是 id 以数字开头的原因,具体问题参考:
是 id 以数字开头的原因,简单的<div id="1">test<div>就能复现这个效果。document.getElementById('1')能够选中,但document.querySelector('#1')不能,因为 HTML5 允许 id 以数字开头而 CSS 不允许
0x31 是 ‘1’ 的 Unicode 编码值,Copy selector 的时候 Chrome 做了一个智能的 escape
参考: