本文最后更新于:2022年11月28日 下午
前言
作为一个开发者,吾辈在工作之后开始使用了 markdown 作为一切文档的基本格式。由此衍生出来了一些处理 markdown 的需要,特别是在笔记工具使用了基于 markdown 的 joplin 之后,这种需求确切的开始存在了。
下面列出一些常见的需求
- 在 vscode 中访问和编辑笔记
- 从笔记中导出 blog 需要的文件
- 从 markdown 生成 epub 文件和网站
- 从 markdown 生成 pdf 文件以便分享
- 更多。。。
工具库
markdown 相关的工具库有很多,举几个知名的
- markdown-it: 很早的一个 markdown 实现,包括 vscode 在内的许多工具都使用它
- marked: 一个更古老的工具,npm 下载量更多,但我没有找到知名的用例
- remark: 一个离散的 markdown 工具,几乎所有功能都交由插件系统实现,非常灵活,被 mdx 等知名工具使用
- mdast: 更底层的 markdown ast 抽象,提供了各种各样的工具包,是 remark 的底层依赖
虽然有这么多的工具,但最终吾辈选择了 mdast,原因是多方面的
- 支持仅修改 markdown 而不将之转换为 html,其他工具一般只能将自定义操作作为插件嵌入到渲染流程中,而不能单独获取和处理 ast,它是吾辈已知唯一能这样做的库
- mdast 提供 markdown 的 ast 抽象,并且对开发者暴露,也能与其他工具很好的结合,例如 astexplorer 支持查看基于 mdast 抽象的 markdown 语法树
- mdast/remark 同源,但 mdast 层级更低也更快,没有准确的测量但实际用例中快了 5 倍
所以最终选择了 mdast,即便它也有一些缺点,但仍然瑕不掩瑜
- mdast 非常离散化,所需的功能基本都在社区插件包中维护,这意味着要依赖非常多的模块 – 通过自行维护 @liuli-util/markdown-util 解决
- mdast 是 esm only 的,这个社区也开始放弃 cjs 了 – 吾辈也开始这样做了,虽然许多模块仍然支持 cjs,但新的模块已经默认 esm only 了
基本使用
一个最简单的使用示例是将 markdown 转换为 html
1
2
3
4
5
6
7
8
9
10
11
12
13
| import { toHtml } from 'hast-util-to-html'
import { fromMarkdown } from 'mdast-util-from-markdown'
import { gfmFromMarkdown } from 'mdast-util-gfm'
import { toHast } from 'mdast-util-to-hast'
import { gfm } from 'micromark-extension-gfm'
const s = '## Hello **World**!'
const root = fromMarkdown(s, {
extensions: [gfm()],
mdastExtensions: [gfmFromMarkdown()],
})
const r = toHtml(toHast(root)!)
console.log(r)
|
可以看到,比想象中要麻烦一些,必须使用各种插件和工具,只是这个简单的工作我们需要使用 5 个模块,但在下面吾辈会证明这是值得的,也是可以解决的。
这里我们可以先简单封装一下,三个最基本的函数
fromMarkdown: 从 markdown 文本得到 asttoMarkdown: 从 ast 转换为 markdown 文本toHTML: 从 ast 转换为 html 文本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| import {
fromMarkdown as fm,
Options as FmOptions,
} from 'mdast-util-from-markdown'
import { Options as TmOptions, toMarkdown as tm } from 'mdast-util-to-markdown'
import type { Content, Root } from 'mdast'
import {
frontmatterFromMarkdown,
frontmatterToMarkdown,
} from 'mdast-util-frontmatter'
import { frontmatter } from 'micromark-extension-frontmatter'
import { gfm } from 'micromark-extension-gfm'
import { gfmFromMarkdown, gfmToMarkdown } from 'mdast-util-gfm'
import { toHast } from 'mdast-util-to-hast'
import { toHtml as hastToHtml } from 'hast-util-to-html'
export function fromMarkdown(content: string, options?: FmOptions): Root {
return fm(content, {
...options,
extensions: [frontmatter(['yaml']), gfm()].concat(
options?.extensions ?? [],
),
mdastExtensions: [
frontmatterFromMarkdown(['yaml']),
gfmFromMarkdown(),
].concat(options?.mdastExtensions ?? []),
})
}
export function toMarkdown(ast: Content | Root, options?: TmOptions): string {
return tm(ast, {
...options,
extensions: [frontmatterToMarkdown(['yaml']), gfmToMarkdown()].concat(
options?.extensions ?? [],
),
})
}
export function toHtml(node: Root): string {
return hastToHtml(toHast(node)!)
}
|
为了方便,我们默认引入了 gfm/yaml 这两个插件。下面的示例代码将直接使用这三个函数,现在重新完成之前转换 markdown 为 html 的需求
1
2
3
| const s = '## Hello **World**!'
const r = toHtml(fromMarkdown(s))
console.log(r)
|
可以看到,现在使用变得简单一些了。
markdown ast
然后,就是 ast 部分,mdast 抽象了 markdown 的语法树,可以在 astexplorer 中检查一段 markdown 的语法树。
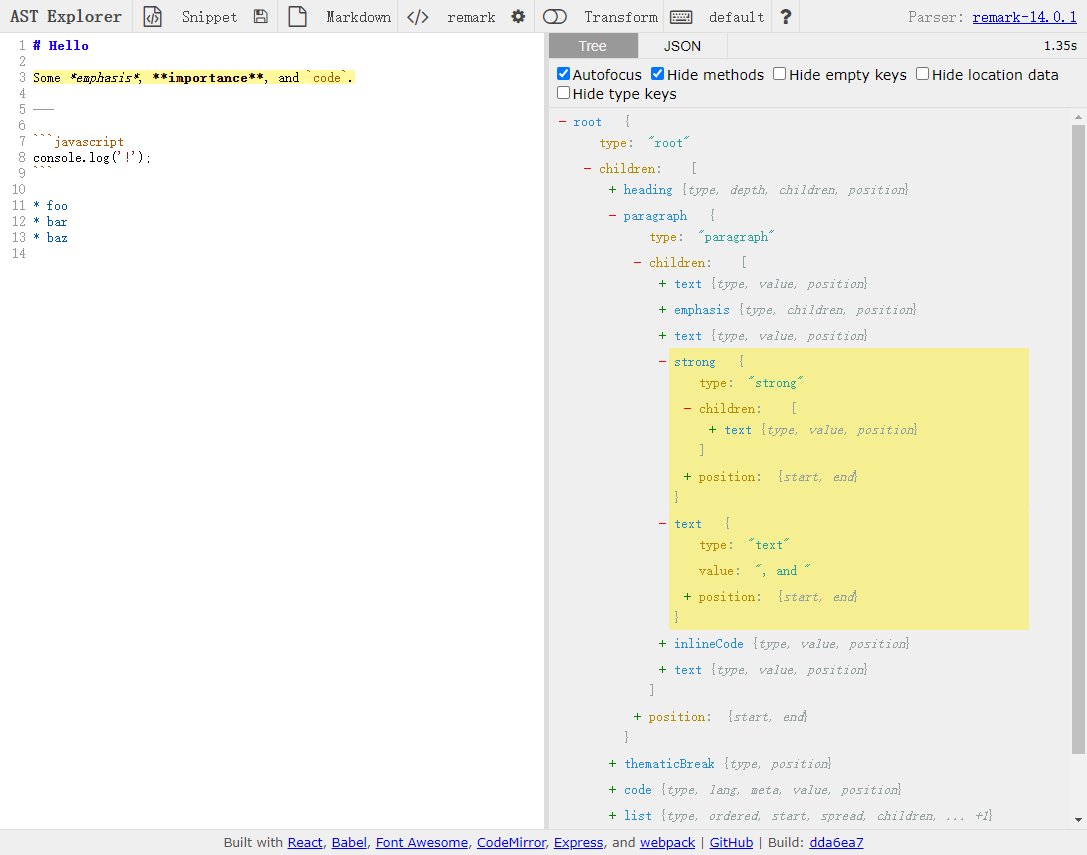
实际上,它就是一个嵌套的 json 对象。当得到 ast 之后,就可以对他进行操作,例如,最简单的遍历
1
2
3
4
5
6
7
8
| import { Node, visit } from 'unist-util-visit'
import { fromMarkdown } from '../parse'
const s = '## Hello **World**!'
const root = fromMarkdown(s)
visit(root, (node: Node) => {
console.log(node.type)
})
|
或者对它做一些修改,例如将粗体的替换为普通文本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import { Node, Parent } from 'unist'
import { Strong } from 'mdast'
import { visit } from 'unist-util-visit'
import { fromMarkdown, toMarkdown } from '../parse'
const s = '## Hello **World**!'
const root = fromMarkdown(s)
visit(root, (node: Node) => {
if ('children' in (node as any)) {
const p = node as Parent
p.children = p.children.flatMap((item) =>
item.type === 'strong' ? (item as Strong).children : [item],
)
}
})
console.log(toMarkdown(root))
|
嗯,引入了 3 个模块。我们可以更进一步封装一个适用于 mdast 的 flatMap
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
export function flatMap<T extends Node>(
tree: T,
fn: (node: Node, i: number, parent?: Parent) => Node[],
): T {
function transform(node: Node, i: number, parent?: Parent): Node[] {
if ('children' in node) {
const p = node as unknown as Parent
p.children = p.children.flatMap((item, i) => transform(item, i, p)) as any
}
return fn(node, i, parent)
}
return transform(tree, 0, undefined)[0] as T
}
|
使用 flatMap 重新完成它
1
2
3
4
5
6
7
8
9
10
| import { fromMarkdown, toMarkdown } from '../parse'
import { flatMap } from '../utils'
import { Strong } from 'mdast'
const s = '## Hello **World**!'
const root = fromMarkdown(s)
flatMap(root, (item) =>
item.type === 'strong' ? (item as Strong).children : [item],
)
console.log(toMarkdown(root))
|
嗯,只需要一步就完成了。嗯,为了性能吾辈并未将 flatMap 实现为返回一个新的 ast,当然,如果期望如此,无论如何都可以使用 immer 之类的库来实现 immutable。
转换链接
好吧,来看一些真实的需求
第一个是修改 markdown 中的链接,例如希望将链接中的资源都转换为 cdn 地址,这里使用 google photos 作为示例
原始 markdown 内容
1
2
| 

|
希望转换得到的 markdown 内容,即为 google 图片的地址添加代理服务,避免无法在 blog 显示的错误。同时也不能转换不相关的资源
1
2
| 

|
实际上这件事情很简单,我们只需要过滤出来需要的节点并且修改就好了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import { fromMarkdown, toMarkdown } from '../parse'
import { Image } from 'mdast'
import { selectAll } from 'unist-util-select'
const s = `


`.trim()
const root = fromMarkdown(s)
;(selectAll('image', root) as Image[])
.filter((item) =>
item.url.startsWith('https://lh3.googleusercontent.com/pw/'),
)
.forEach(
(item) => (item.url = `https://image-proxy.rxliuli.com/?url=${item.url}`),
)
console.log(toMarkdown(root))
|
修改元数据
我们还可以修改 markdown 的元数据,例如我们从 hexo 转换为 hugo 时,会需要转换它们的元数据。
例如 hexo 的元数据一般格式是
1
2
3
4
5
6
| layout: post
title: 2. Importing and exporting notes
abbrlink: 2ba8366ac77c4a93b9eb7595d1343eb6
tags: []
date: 1667644025956
updated: 1667644025956
|
而 hugo 的是
1
2
3
4
5
| title: 2. Importing and exporting notes
slug: 2ba8366ac77c4a93b9eb7595d1343eb6
tags: []
date: 2022-11-05T10:27:05.956Z
lastmod: 2022-11-05T10:27:05.956Z
|
无论如何,它们的 markdown 不会完全一样,这时候我们需要做一些简单的转换。
首先我们还是先封装 getYamlMeta/setYamlMeta 这些工具函数吧
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| import { Root, YAML } from 'mdast'
import { select } from 'unist-util-select'
import * as yaml from 'yaml'
export function getYamlMeta<T>(root: Root): T {
const r = select('yaml', root)
return yaml.parse(r ? (r as YAML).value : '')
}
export function setYamlMeta(root: Root, meta: any) {
const r = select('yaml', root) as YAML
if (r) {
r.value = yaml.stringify(meta).trim()
} else {
root.children.unshift({
type: 'yaml',
value: yaml.stringify(meta).trim(),
} as YAML)
}
}
|
然后就可以简单的修改元数据了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| import { fromMarkdown, toMarkdown } from '../parse'
import { getYamlMeta, setYamlMeta } from '../utils'
const s = `
---
layout: post
title: 2. Importing and exporting notes
abbrlink: 2ba8366ac77c4a93b9eb7595d1343eb6
tags: []
date: 1667644025956
updated: 1667644025956
---
`.trim()
interface HexoMeta {
layout: string
title: string
abbrlink: string
tags: string[]
date: number
updated: number
}
interface HugoMeta {
title: string
slug: string
tags: string[]
date: string
lastmod: string
}
const root = fromMarkdown(s)
const meta = getYamlMeta(root) as HexoMeta
setYamlMeta(root, {
title: meta.title,
slug: meta.abbrlink,
tags: meta.tags,
date: new Date(meta.date).toISOString(),
lastmod: new Date(meta.updated).toISOString(),
} as HugoMeta)
console.log(toMarkdown(root))
|
清除额外的空格
可能不太为人所知的是,markdown 对东亚字符的支持一直有问题,一个之前遇到的例子是如果粗体的结尾使用中文符号,则粗体不会生效。
例如
1
| **真没想到我这么快就要死了,**她有些自暴自弃地想着。
|
会被渲染为
**真没想到我这么快就要死了,**她有些自暴自弃地想着。
这很奇怪,但确实存在,commonmark 的实现 markdown-it 官方的建议是添加额外的空格,例如修改为
1
| **真没想到我这么快就要死了,** 她有些自暴自弃地想着。
|
这样就能正确渲染粗体了
真没想到我这么快就要死了, 她有些自暴自弃地想着。
但这会渲染额外的空格,如果期望最终 html 中不渲染这个额外的空格怎么办?可以使用程序删除掉它。
这里有两种方法
- 直接修改 markdown ast 清除空格
- 转换为 html 语法树之后再修改
由于这里更关注 markdown,所以会采用第一种方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| import { Strong, Text } from 'mdast'
import { fromMarkdown } from '../parse'
import { toHtml } from '../stringify'
import { flatMap } from '../utils'
const s = `**真没想到我这么快就要死了,** 她有些自暴自弃地想着。`
const root = fromMarkdown(s)
console.log(toHtml(root))
flatMap(root, (item, i, p) => {
if (item.type === 'strong') {
const v = item as Strong
const next = p!.children[i + 1]
const s = (v.children[0] as Text).value
if (s) {
const last = s.slice(s.length - 1)
if (
next &&
next.type === 'text' &&
[',', '。', '?', '!', '〉'].includes(last) &&
next.value.startsWith(' ')
) {
next.value = next.value.trim()
}
}
}
return [item]
})
console.log(toHtml(root))
|
创建插件
现在,我们可以来谈一下 mdast 中的插件了,更准确的说是 mdast-util-from-markdown/mdast-util-to-markdown 所支持的插件系统。我们上面写的那些其实都可以封装为插件
例如最初的转换链接可以封装为插件,可以封装为 MdastExtensions 插件以便在 transforms hooks 中转换 ast
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| import { fromMarkdown, toMarkdown } from '../parse'
import { Image } from 'mdast'
import { selectAll } from 'unist-util-select'
import { Extension } from 'mdast-util-from-markdown'
function googleImageProxyFromMarkdown(): Extension {
return {
transforms: [
(root) => {
;(selectAll('image', root) as Image[])
.filter((item) =>
item.url.startsWith('https://lh3.googleusercontent.com/pw/'),
)
.forEach(
(item) =>
(item.url = `https://image-proxy.rxliuli.com/?url=${item.url}`),
)
},
],
}
}
const root = fromMarkdown(s, {
mdastExtensions: [googleImageProxyFromMarkdown()],
})
console.log(toMarkdown(root))
|
也可以封装为输出插件,在 handlers hooks 中处理 image 类型的 ast
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import { fromMarkdown, toMarkdown } from '../parse'
import { Image } from 'mdast'
import { Options } from 'mdast-util-to-markdown'
function googleImageProxyToMarkdown(): Options {
return {
handlers: {
image(node) {
const l = node as Image
if (l.url.startsWith('https://lh3.googleusercontent.com/pw/')) {
l.url = `https://image-proxy.rxliuli.com/?url=${l.url}`
}
return ``
},
},
}
}
const root = fromMarkdown(s)
console.log(
toMarkdown(root, {
extensions: [googleImageProxyToMarkdown()],
}),
)
|
就吾辈而言,一般不会将这种操作封装为插件,而是封装为简单的函数,接收一个 ast 并返回一个 ast 的函数,在需要时直接使用即可。除非一些明显适合使用插件的场景,例如要支持新的语法,例如 [[wiki]] 链接之类的,对这个插件感兴趣可以查看 https://github.com/rxliuli/mami/blob/master/packages/plugin-obsidian/src/utils/wiki.ts。
结语
markdown 是一个有趣的格式,现在几乎所有开发者相关的平台(非国内)都支持它,所以自然而然衍生了很多相关的工具和模块,而基于个人独特的需求则衍生了更多的东西。就吾辈而言,吾辈创建的与 markdown 相关的工具或库包括