本文最后更新于:2025年2月26日 下午
背景 最近使用 Cloudflare D1 作为服务端的数据库,ORM 选择了很多人推荐的 Prisma,但使用过程中遇到了一些问题,主要包括
不支持 D1 的 batch 批处理,完全没有事务 https://www.prisma.io/docs/orm/overview/databases/cloudflare-d1#transactions-not-supported
不支持复杂查询,例如多表 Join SQL 语法 https://github.com/prisma/prisma/discussions/12715
单次查询很慢,通常在 200ms 以上,这很奇怪 ,吾辈相信这与 prisma 内部使用 wasm 导致初始化时间更长有关 https://github.com/prisma/prisma/discussions/23646#discussioncomment-9059560
不支持事务 首先说一下第一个问题,Cloudflare D1 本身并不支持事务,仅支持使用 batch 批处理,这是一种有限制的事务。https://developers.cloudflare.com/d1/worker-api/d1-database/#batch
例如
1 2 3 4 5 6 7 const companyName1 = `Bs Beverages` const companyName2 = `Around the Horn` const stmt = env.DB .prepare (`SELECT * FROM Customers WHERE CompanyName = ?` )const batchResult = await env.DB .batch ([bind (companyName1),bind (companyName2),
而如果你使用 Prisma 的 $transaction 函数,会得到一条警告。
1 prisma:warn Cloudflare D1 does not support transactions yet. When using Prisma's D1 adapter, implicit & explicit transactions will be ignored and run as individual queries, which breaks the guarantees of the ACID properties of transactions. For more details see https://pris.ly/d/d1-transactions
这条警告指向了 cloudflare/workers-sdk ,看起来是 cloudflare d1 的问题(当然,不支持事务确实是问题),但也转移了关注点,问题是为什么 prisma 内部不使用 d1 batch 函数呢?嗯,它目前不支持,仅此而已,检查 @prisma/adapter-d1 的事务实现 。
不支持复杂查询 例如下面这个统计查询,统计 + 去重,看起来很简单?
1 2 3 SELECT spamUserId, COUNT (DISTINCT reportUserId) as reportCountFROM SpamReport GROUP BY spamUserId;
你在 prisma 中可能会想这样写。
1 2 3 4 5 6 const result = await context.prisma .spamReport .groupBy ({by : ['spamUserId' ],_count : {reportUserId : { distinct : true },
不,prisma 不支持,检查已经开放了 4 年 的 issue#4228 。
顺便说一句,drizzle 允许你这样做。
1 2 3 4 5 6 7 const result = await context.db select ({spamUserId : spamReport.spamUserId ,reportCount : countDistinct (spamReport.reportUserId ),from (spamReport)groupBy (spamReport.spamUserId )
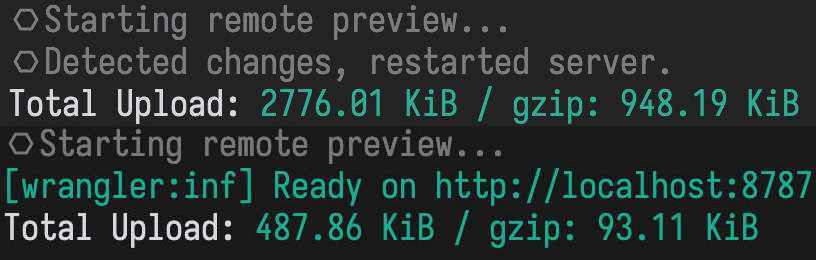
单次查询很慢 这一点没有真正分析过,只是体感上感觉服务端 API 请求很慢,平均时间甚至达到了 1s,而目前最大的一张表数据也只有 30+k,而大多数其他表还不到 1k,这听起来不正常。但事后来看,从 prisma 切换到 drizzle 之后,bundle 尺寸从 2776.05 KiB / gzip: 948.21 KiB 降低到了 487.87 KiB / gzip: 93.10 KiB,gzip 之后甚至降低了 90%,这听起来并不那么不可思议了。
有人做了一些测试,似乎批量插入 1k 条的性能问题更糟糕,甚至超过了 30s。https://github.com/prisma/prisma/discussions/23646#discussioncomment-10965747
踩坑 说完了 Prisma 的这么多问题,接下来说一下在迁移过程中踩到的坑。
坑 1: 从 schema.prisma 生成 schema.ts 有问题 在迁移时,首先使用 Grok 从 schema.prisma 自动生成了 drizzle 需要的 schema.ts。但发现了以下问题
原本的表结构
1 2 3 4 5 CREATE TABLE "LocalUser" (NOT NULL PRIMARY KEY ,NOT NULL DEFAULT CURRENT_TIMESTAMP ,NOT NULL ,
Grok 自动转换生成
1 2 3 4 5 6 7 8 9 10 11 export const localUser = sqliteTable ('LocalUser' , {id : text ('id' )primaryKey ()default (sql`uuid()` ),createdAt : integer ('createdAt' , { mode : 'timestamp' })default (sql`CURRENT_TIMESTAMP` )notNull (),updatedAt : integer ('updatedAt' , { mode : 'timestamp' })default (sql`CURRENT_TIMESTAMP` )notNull (),
这里的自动转换有几个问题
sql`uuid()` 在 prisma 中由应用抽象层填充,但 schema.ts 里使用 sql`uuid()`,这里应该同样由应用抽象层填充updatedAt 有相同的问题,schema.ts 里使用了 sql`CURRENT_TIMESTAMP`
createdAt/updatedAt 实际上是 text 类型,而 schema.ts 里使用了 integer,这会导致无法向旧表插入数据,也无法正确查询到对应的字段,只会得到 Invalid Date
实际上需要修改为
1 2 3 4 5 6 7 8 9 export const localUser = sqliteTable ('LocalUser' , {id : text ('id' ).primaryKey ().$defaultFn(uuid),createdAt : text ('createdAt' )notNull ()() => new Date ().toISOString ()),updatedAt : text ('createdAt' )notNull ()() => new Date ().toISOString ()),
坑 2: db.batch 批量查询有时候会出现返回的 Model 填充数据错误的问题 嗯,在 join 查询时 drizzle 并不会自动解决冲突的列名。假设有 User 和 ModList 两张表
id
screenName
name
user-1
user-screen-name
user-name
id
name
userId
modlist-1
modlist-name
user-1
然后执行以下代码,非批量查询的结果将与批量查询的结果不同。
1 2 3 4 5 6 7 8 9 const query = dbselect ()from (modList)innerJoin (user, eq (user.id , modList.userId ))where (eq (modList.id , 'modlist-1' ))const q = query.toSQL ()const stmt = context.env .DB .prepare (q.sql ).bind (...q.params )console .log ((await stmt.raw ())[0 ])console .log ((await context.env .DB .batch ([stmt]))[0 ].results [0 ])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 'modlist-1' ,'modlist-name' ,'user-1' ,'user-1' ,'user-screen-name' ,'user-name' ,id : 'user-1' ,name : 'user-name' ,userId : 'user-1' ,screenName : 'user-screen-name' ,
这里的 ModList 和 User 中有冲突的列名 id/name,在批量查询时后面的列将会覆盖掉前面的,参考相关的 issue。
https://github.com/cloudflare/workers-sdk/issues/3160 https://github.com/drizzle-team/drizzle-orm/issues/555
需要手动指定列的别名。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 db.select ({modList : {id : sql<string >`${modList.id} ` .as ('modlist_id' ),name : sql<string >`${modList.name} ` .as ('modlist_name' ),user : {id : sql<string >`${user.id} ` .as ('user_id' ),screenName : sql<string >`${user.screenName} ` .as ('user_screen_name' ),name : sql<string >`${user.name} ` .as ('user_name' ),from (modList)innerJoin (user, eq (user.id , modList.twitterUserId ))where (eq (modList.id , 'modlist-1' ))
然后就会得到一致的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 'modlist-1' ,'modlist-name' ,'user-1' ,'user-screen-name' ,'user-name' modlist_id : 'modlist-1' ,modlist_name : 'modlist-name' ,user_id : 'user-1' ,user_screen_name : 'user-screen-name' ,user_name : 'user-name'
甚至可以实现一个通用的别名生成器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import {AnyTable ,TableConfig ,InferSelectModel ,SQL ,from 'drizzle-orm' export function getTableAliasedColumns<T extends AnyTable <TableConfig >>(table : T,type DataType = InferSelectModel <T>const tableName = getTableName (table)const columns = getTableColumns (table)return Object .entries (columns).reduce ((acc, [columnName, column] ) => {as any )[columnName] = sql`${column} ` .as (`${tableName} _${columnName} ` ,return accas {in keyof DataType ]: SQL .Aliased <DataType [P]>
然后就不再需要手动设置别名,而且它还是类型安全的!
1 2 3 4 5 6 7 db.select ({modList : getTableAliasedColumns (modList),user : getTableAliasedColumns (user),from (modList)innerJoin (user, eq (user.id , modList.twitterUserId ))where (eq (modList.id , 'modlist-1' ))
总结 数据迁移时兼容性最重要,修改或优化 schema 必须放在迁移之后。整体上这次的迁移结果还是挺喜人的,后续开新坑数据库 ORM 可以直接用 drizzle 了。