实现一个玩具 lisp 运行时与解析器
本文最后更新于:2022年6月21日 凌晨
前言
之前看元循环求值器一节中使用 lisp 实现了一个 lisp 的运行时,吾辈也尝试使用 ts 来实现它。首先,这里展示一张曾经在书中出现过的图,表示一个运行时的基本组成是由 eval 和 apply 组成(看起来很像太极就是了)。eval 负责执行一个表达式,在 lisp 中,所有的代码都是表达式,这没什么问题。apply 则负责执行一个函数,将计算实参列表,并创建一个新的闭包环境绑定到形参上。

环境是一个有趣的话题,最初,吾辈了解到的是代换模型,即 (+ (+ 1 2) 3) 也可以被替换为 (+ 1 2 3)。后来,接触到修改变量后,每个函数就会绑定环境,然后动态获取某些值。
例如执行代码
1 | |

实现运行时
最初,吾辈也尝试使用 cons 实现,但后来发现面向对象更适合做这种事情(抽象语法树有不同的类型)。
考虑到复杂度的问题,目前实现了以下几种 ast
- primitive: 原始值,例如 number/boolean/string
- variable: 变量,从当前环境中获取值
- define: 在当前环境中定义新的值
- set: 修改当前环境中指定的值
- if: 条件判断,类似于三元表达式
- cond: 条件判断,类似于 if/else-if/else
- begin: 一系列表达式,结果为最后一个表达式的值
- lambda: 函数,包含参数、函数体与定义时的环境,可以被 apply 执行
- procedure: 一个需要执行的函数+参数
先定义基础的 ast 接口,其中 eval 是每种 ast 都必须实现的方法,apply 则仅在 lambda ast 中存在。
1 | |
环境
然后实现 Env 环境变量,应该能够获取、新增、修改以及扩展为一个新的环境
1 | |
接下来我们分别实现每一个
原始值
原始值很简单,例如 1,2,3,4,5… 这样的数字,或 true/false 布尔值,亦或是 “hello world” 这种字符串,它们都是原始值,可以直接声明和使用,所以 ast 也仅仅是保存值,并且执行的时候返回而已。
1 | |
variable/define/set 环境
variable/define/set 都是在操作环境,分别是获取、新增和修改。
有两点需要注意的地方
- variable 有点特殊,因为某些函数预先定义在语言中,例如
+ - * / cons car cdr,它们不需要定义就可以使用(类似于浏览器的native function),所以这里有一个仅在内部使用的PrimitiveLambdaAst类型,可以看到其中实现了+ > < =这几个原生函数。 - 环境应该保存指向上一个环境的索引,这里为了简单实现使用了引用复制。

1 | |
if/cond 条件判断
条件分支的 ast 很简单,许多语言中都有这种功能。

if/cond 可以相互替代,所以可以仅实现一种,然后替换另一种即可,这里由于比较简单所以实现了两种。
1 | |
sequence/procedure
sequence 表示一系列表达式,全部执行并返回最后一个的结果。例如以下代码应该返回 3
1 | |
1 | |
lambda/procedure
procedure/lambda 是最有趣的一部分,前者负责定义一个函数,后者则负责具体的调用。lambda ast 执行仅绑定了环境,并未真的执行。apply 则才会开辟一个新的环境,并将参数绑定新的环境上,然后执行函数体的代码。procedure 则计算一个表达式,表达式包含函数部分与参数部分,它会分别计算两者并最后应用 lambda ast 的 apply 方法。
考虑以下代码如何执行
1 | |
分为几步看
(lambda (x) (lambda (y) (+ x y)))创建一个函数,它返回一个新的函数((lambda (x) (lambda (y) (+ x y))) 1)应用了上面的函数,创建了一个新的环境,x 被绑定为 1,返回了一个新的函数,可以被认为转换为了表达式(lambda (y) (+ 1 y))- 应用返回的函数,创建新的环境,将 y 绑定到 2
- 是一个原生函数
+,直接得到结果 3

1 | |
统一入口
然后,统一的入口 evalLisp/applyLisp 就很简单了
1 | |
验证一下
1 | |
解析代码为 ast
上面实现了执行 lisp ast 的功能,但如何将 lisp 代码解析为这种 ast 还没有实现,下面就来完成这一步。
解析代码为字符流
简单的处理为一个 token 数组很简单
1 | |
将字符流结构化
但我们需要结构化的,所以还需要做一次转换
基本思路是每次处理一个字符
- 如果是
(,则添加一个临时数组存储之后的值,直到遇到)为止 - 如果是
),则将当前的临时数组合并到上一个临时数组 - 如果是其他字符,则将之追加到当前临时数组中
- 如果到了结尾,则返回当前的数组
- 初始数组是
[[]],最后返回res[0][0]
这是一个基本的流程图
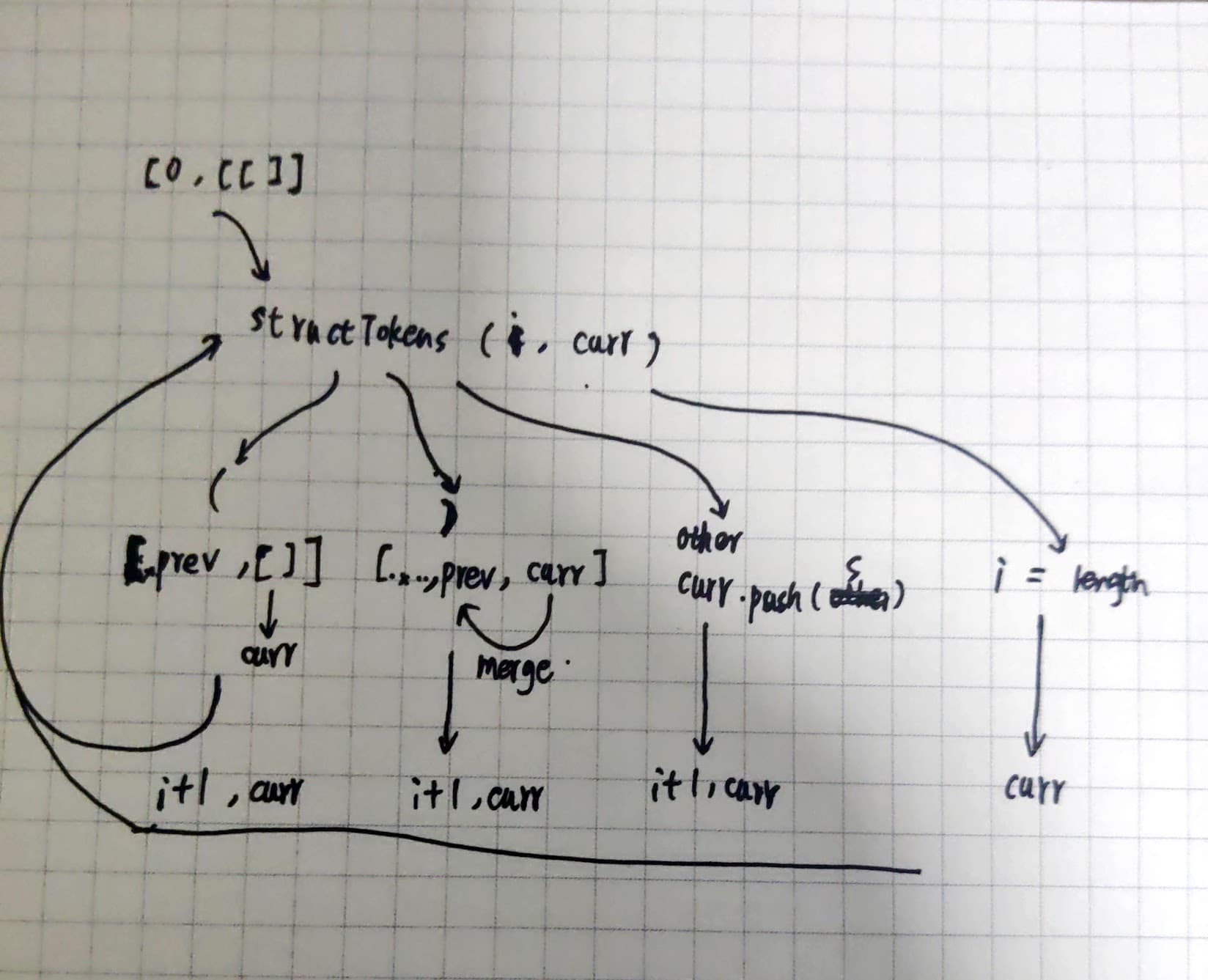
下面是解析代码 (begin (define x 1) (define y 2) (+ x y)) 的 tokens 流程中数组的状态
| step | code | arr |
|---|---|---|
| init | [[]] |
|
| 1 | ( |
[[], []] |
| 2 | begin |
[[], [begin]] |
| 3 | ( |
[[], [begin], []] |
| 4 | define |
[[], [begin], [define]] |
| 5 | define |
[[], [begin], [define]] |
| 6 | x |
[[], [begin], [define, x]] |
| 7 | 1 |
[[], [begin], [define, x, 1]] |
| 8 | ) |
[[], [begin, [define, x, 1]]] |
| 9 | ( |
[[], [begin, [define, x, 1]], []] |
| 10 | define |
[[], [begin, [define, x, 1]], [define]] |
| 11 | y |
[[], [begin, [define, x, 1]], [define, y]] |
| 12 | 2 |
[[], [begin, [define, x, 1]], [define, y, 2]] |
| 13 | ) |
[[], [begin, [define, x, 1], [define, y, 2]]] |
| 14 | ( |
[[], [begin, [define, x, 1], [define, y, 2]], []] |
| 15 | + |
[[], [begin, [define, x, 1], [define, y, 2]], [+]] |
| 16 | x |
[[], [begin, [define, x, 1], [define, y, 2]], [+, x]] |
| 17 | y |
[[], [begin, [define, x, 1], [define, y, 2]], [+, x, y]] |
| 18 | ) |
[[], [begin, [define, x, 1], [define, y, 2], [+, x, y]]] |
| 19 | ) |
[[[begin, [define, x, 1], [define, y, 2], [+, x, y]]]] |
具体实现
1 | |
转换为 ast
最终,我们将结构化的 token 转换为 ast
1 | |
我们可以验证它的正确性
1 | |
结语
在上面,吾辈实现了 lisp 的玩具运行时和解析器,虽然还不支持许多 lisp 的功能(例如 ' 引用功能),但核心的功能已经实现了,它可以完成一些基本的数值逻辑运算了。另一种有趣的思路是编译器,它不直接运行 lisp 代码,而是将 lisp 代码编译为一种其他可以运行的代码,例如将 lisp 代码编译为汇编代码执行,或者更有趣的方法是 – 编译为 js,就像 ts 做的一样,那样它就可以与 js 互操作了。