本文最后更新于:2025年4月3日 上午
背景
最近在做一些服务端相关的事情,使用了 Cloudflare Workers + D1 数据库,在此过程中,遇到了一些数据库相关的问题,而对于前端而言数据库是一件相当不同的事情,所以在此记录一下。
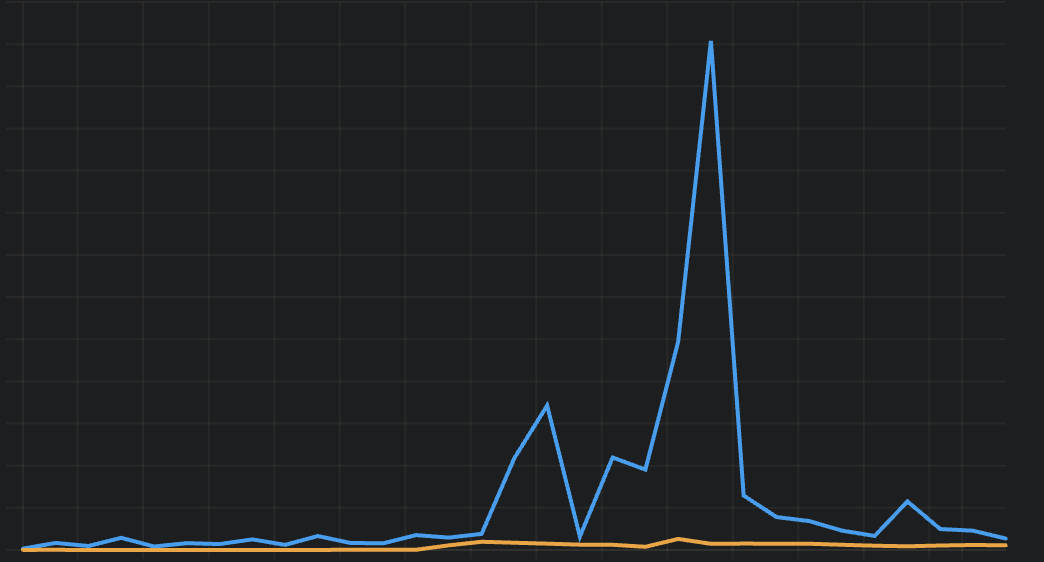
下图是最近 30 天的请求记录,可以看到数据库查询变化之剧烈。
发现问题
解决问题的前提是发现问题,有几个方法可以更容易留意到相关问题。
- 检查 D1 仪表盘,确定数据库操作是否有异常增长
- 检查查询语句及读取/写入行数,特别关注 count/rows read/rows written 排在前列的查询
- 使用
c.env.DB.prepare('<sql>').run()).meta 并检查返回的 meta,它包含这个 sql 实际读取/写入的行数
使用 batch 批量请求
首先明确一点,Workers 和 D1 虽然同为 Cloudflare 的服务,但同时使用它们并不会让 D1 变得更快。拿下面这个简单的查询举例,它的平均响应时间(在 Workers 上发起查询到在 Workers 上得到结果)超过了 200ms。
1
| await db.select().from(user).limit(1)
|
所以在一个接口中包含大量的数据库操作时,应该尽量使用 d1 batch 来批量完成,尤其是对于写入操作,由于没有只读副本,它只会比查询更慢。例如
1
2
| await db.insert(user).values({...})
await db.insert(tweet).values({...})
|
应该更换为
1
2
3
4
| await db.batch([
db.insert(user).values({...}),
db.insert(tweet).values({...})
])
|
这样只会向 d1 发出一次 rest 请求即可完成多个数据库写入操作。
ps1: prisma 不支持 d1 batch,吾辈因此换到了 drizzle 中,参考 记录一次从 Prisma 到 Drizzle 的迁移。
ps2: 使用 batch 进行批量查询时需要小心,尤其是多表有同名的列时,参考 https://github.com/drizzle-team/drizzle-orm/issues/555
update 操作排除 id
在 update 时应该排除 id(即使实际上没有修改)。例如下面的代码,将外部传入的 user 传入并更新,看起来没问题?
1
| await db.update(user).set(userParam).where(eq(user.id, userParam.id))
|
实际执行的 SQL 语句
1
| update "User" set "id" = ?, "screenName" = ?, "updatedAt" = ? where "User"."id" = ?
|
然而,一旦这个 id 被其他表通过外键引用了。它就会导致大量的 rows read 操作。例如另一张名为 tweet 的表有一个 userId 引用了这个字段,并且有 1000 行数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| await db.batch([
db.insert(user).values({
id: `test-user-1`,
screenName: `test-screen-name-1`,
name: `test-name-1`,
}),
...range(1000).map((it) =>
db.insert(tweet).values({
id: `test-tweet-${it}`,
userId: `test-user-1`,
text: `test-text-${it}`,
publishedAt: new Date().toISOString(),
}),
),
] as any)
|
然后进行一次 update 操作并检查实际操作影响的行数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| const userParam: InferInsertModel<typeof user> = {
id: 'test-user-1',
screenName: 'test',
}
const r = await db.update(user).set(userParam).where(eq(user.id, userParam.id))
console.log(r.meta)
|
可以看到 rows read 突然增高到了 2005,而预期应该是 1,考虑一下关联的表可能有数百万行数据,这是一场噩梦。而如果确实排除了 id 字段,则可以看到 rows read/rows written 确实是预期的 1,无论它关联了多少数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| const r = await db
.update(user)
.set(omit(userParam, ['id']))
.where(eq(user.id, userParam.id))
console.log(r.meta)
|
可以说这是个典型的愚蠢错误,但前端确实对数据库问题不够敏锐。
避免 count 扫描全表
吾辈在 D1 仪表盘中看到了下面这个 SQL 语句在 rows read 中名列前矛。像是下面这样
1
| SELECT count(id) as num_rows FROM "User";
|
可能会在仪表盘看到 rows read 的暴增。
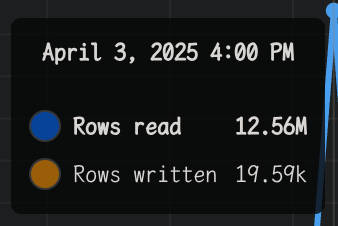
这导致了吾辈在实现分页时直接选择了基于 cursor 而非 offset,而且永远不会给出总数,因为即便 id 有索引,统计数量也会扫描所有行。这也是一个已知问题:https://community.cloudflare.com/t/full-scan-for-simple-count-query/682625
避免多表 leftJoin
起因是吾辈注意到下面这条 sql 导致了数十万的 rows read。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| SELECT "modlist"."id",
"modlist"."updatedat",
"modlistsubscription"."action",
Json_group_array(DISTINCT "modlistuser"."twitteruserid"),
Json_group_array(DISTINCT "modlistrule"."rule")
FROM "modlist"
LEFT JOIN "modlistsubscription"
ON "modlist"."id" = "modlistsubscription"."modlistid"
LEFT JOIN "modlistuser"
ON "modlist"."id" = "modlistuser"."modlistid"
LEFT JOIN "modlistrule"
ON "modlist"."id" = "modlistrule"."modlistid"
WHERE "modlist"."id" IN ( ?, ? )
GROUP BY "modlist"."id",
"modlistsubscription"."action";
|
下面是对应的 ts 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| await db
.select({
modListId: modList.id,
updatedAt: modList.updatedAt,
action: modListSubscription.action,
modListUsers: sql<string>`json_group_array(DISTINCT ${modListUser.twitterUserId})`,
modListRules: sql<string>`json_group_array(DISTINCT ${modListRule.rule})`,
})
.from(modList)
.leftJoin(modListSubscription, eq(modList.id, modListSubscription.modListId))
.leftJoin(modListUser, eq(modList.id, modListUser.modListId))
.leftJoin(modListRule, eq(modList.id, modListRule.modListId))
.where(inArray(modList.id, queryIds))
.groupBy(modList.id, modListSubscription.action)
|
可以看到这里连接了 4 张表查询,这种愚蠢的操作吾辈不知道当时是怎么写出来的,也许是 LLM 告诉吾辈的 😂。而吾辈并未意识到这种操作可能会导致所谓的“笛卡尔积爆炸”,必须进行一些拆分。
“笛卡尔积爆炸”是什么?在这个场景下就吾辈的理解而言,如果使用 leftJoin 外连多张表,并且外联的字段相同,那么就是多张表查询到的数据之和。例如下面这条查询,如果 modListUser/modListRule 都有 100 条数据,那么查询的结果则有 100 * 100 条结果,这并不符合预期。
1
2
3
4
5
| db.select()
.from(modList)
.leftJoin(modListUser, eq(modList.id, modListUser.modListId))
.leftJoin(modListRule, eq(modList.id, modListRule.modListId))
.where(eq(modList.id, 'modlist-1'))
|
而如果正确的拆分查询并将数据分组和转换放到逻辑层,数据库的操作就会大大减少。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| await db.batch([
db
.select({
modListId: modListUser.modListId,
twitterUserId: modListUser.twitterUserId,
})
.from(modListUser)
.where(eq(modListUser.modListId, 'modlist-1')),
db
.select({
modListId: modListRule.modListId,
rule: modListRule.rule,
})
.from(modListRule)
.where(eq(modListRule.modListId, 'modlist-1')),
])
|
insert values 写入多条数据
如果 rows written 数量不多,或者没有批处理的需求,那这可能只是过早优化。
这是在优化写入性能时尝试的一个小技巧,可以提升批量写入的性能。考虑下面这个批量插入的代码
1
| await Promise.all(users.map((it) => db.insert(user).values(it)) as any)
|
嗯,这只是个愚蠢的例子,当然要使用 batch 操作,就像上面说的那样。
1
| await db.batch(users.map((it) => db.insert(user).values(it)) as any)
|
但是否忘记了什么?是的,数据库允许在一行中写入多条数据,例如:
1
| await db.insert(user).values(users)
|
不幸的是,sqlite 允许绑定的参数数量有限,D1 进一步限制了它 ,每次参数绑定最多只有 100 个。也就是说,如果我们有 10 列,我们最多在一条 SQL 中插入 10 行,如果批处理数量很多,仍然需要放在 batch 中处理。
幸运的是,实现一个通用的自动分页器并不麻烦,参考 https://github.com/drizzle-team/drizzle-orm/issues/2479#issuecomment-2746057769
1
2
3
4
5
| await db.batch(
safeChunkInsertValues(user, users).map((it) =>
db.insert(user).values(it),
) as any,
)
|
那么,我们实际获得性能收益是多少?
就上面举的 3 个例子进行了测试,每个例子分别插入 5000 条数据,它们在数据库执行花费的时间是
78ms => 37ms => 14ms
吾辈认为这个优化还是值得做的,封装之后它对代码几乎是无侵入的。
总结
服务端的问题与客户端相当不同,在客户端,即便某个功能出现了错误,也只是影响使用者。而服务端的错误可能直接影响月底账单,而且需要一段时间才能看出来,因此需要小心,添加足够的单元测试。解决数据库查询相关的问题时,吾辈认为遵循 发现 => 调查 => 尝试解决 => 跟进 => 再次尝试 => 跟进 => 完成 的步骤会有帮助,第一次解决并不一定能够成功,甚至有可能变的更糟,但持续的跟进将使得及时发现和修复问题变得非常重要。